
What is the Common Closure Principle? Well, the CCP states:
Classes within a component should be grouped together based on the same kind of changes they are susceptible to. When a change affects a component, it should impact all the classes within that component and no other components.
Components, it should be mentioned, are the classes that are cohesive to the use case. So, any classes that might be affected by changes to the use case should be grouped together. But when you move these classes into separate folders, projects, or packages then they are no longer grouped together and thus you are violating the CCP.
/src
—/application
—/domain
—/infrastructure
—/web
/templates
/tests
These “layer folders” with “functional folders” underneath the layer folders put classes that perform similar functions into the same folders. However, a single component is spread out everywhere as we see in the image below of the same repository
/src
—/clean-architecture-core
——/interfaces
——/services
—/clean-architecture-infrastructure
——/data
——/errors
—/clean-architecture-use-cases
——/users
––––/create
––––/delete
––––/update
As you probably noticed, there is this thing with Uncle Bob where his knowledge, his ideas, his method, his explanation about how everything connect together (Agile, TDD, Clean Code, Architecture and other principles) is scattered everywhere in various books, blogs, conference and even videos behind paywalls. Not even counting his own ideas evolving over time, as they should. So if one read or watch only one or a few things it will sure miss some parts of the context.
Feature Folders
An application grows horizontally, not vertically. That is to say, you are constantly adding more features to the application, but hardly ever add more layers. You need to plan for this expansion so that as your code grows it is not only easier to find the related classes to the component, but you can easily split the code base into separate packages and services as it grows. You must make it simple to find the seams in your code where the code can be split. Folders are obvious ways to create these seams.
/src
—/domains
——/user
———/create
————createCommand
————createEndpoint
————createEndpointRequest
————createEndpointResponse
————createHandler
———/delete
———/update
We have a folder that contains the different domains of the application. Each domain has a top-level folder that is the name of that domain, and inside of each folder is a sub-folder for each use case (feature) that relates to that domain. Inside of those folders are the classes that are cohesive to that use case (feature).
feature structure is indeed a good start, especially for small, personal, project. Then it depend on how much you trust the stability of external stuff and how much trouble it means for the code if some external stuff changes.
CA is like 2 architectures in 1.
-
Architecture 1 is a version of Port and Adapter, which focus on dependency and to understand it one also have to understand where it is coming from. That is : Uncle Bob have been doing this for a long time and dependencies were a lot more of a problem when changes impacted tons of other components and compiling them took hours or days like it once was the case.
-
Thus component coupling principles (ADP, SDP, SAP) helped him to determine how to split component in a more efficient way, that is to have dependencies go in the direction of stability (SDP) and putting abstract elements in the more stable components (SAP) (a stable component is a component that should have less reason to change, because again changes to a component will impact all the components that depend on it). Which have a tendency to split even further the number of components. Principles of Component Coupling https://devlead.io/DevTips/PrinciplesOfComponentCoupling
-
Acyclic Dependencies Principle
- Design your software in such a way that the dependencies between your components do not form a cycle. The resulting component dependency structure will form a Directed Acyclic Graph — such as a tree structure. Draw your component graph as a tree and make sure all the arrows point downward. Then rest assured that your dependencies do not form a cycle.
-
Stable Dependencies Principle
- Design your software in such a way that any given component depends on other components that are more stable than it is. In other words, the dependencies within a component architecture should be pointing in the direction of increasing stability. This will ensure that components that need to change frequently will be easy to change and that the stable components that others depend on will not change nearly as often.
-
Stable Abstractions Principle
- Design your software in such a way that components are as abstract as they are stable. This supports the Stable Dependencies Principle and promotes flexibility by ensuring that stable components are easy to extend, even though they are hard to change. This is achieved by applying the Open/Closed Principle, which enables us to easily extend functionality without modifying existing code. This approach also works best when adhering to the Dependency Inversion Principle, which states that dependencies should point towards abstractions and not concretions. This provides very effective dependency management for software components.
-
Acyclic Dependencies Principle
- Dependencies also slow things down if you want to tests things. Having to load unrequired dependencies to execute your unit tests (be it a webserver or ui framework or just unneeded dlls) may make them a lot slower than if you don’t.
-
Thus component coupling principles (ADP, SDP, SAP) helped him to determine how to split component in a more efficient way, that is to have dependencies go in the direction of stability (SDP) and putting abstract elements in the more stable components (SAP) (a stable component is a component that should have less reason to change, because again changes to a component will impact all the components that depend on it). Which have a tendency to split even further the number of components. Principles of Component Coupling https://devlead.io/DevTips/PrinciplesOfComponentCoupling
-
Architecture 2 is Bob’s version of BCE, which focus on features, Use Cases, as in the name given to user stories before Agile was a thing. It’s usually a vertical slice of the project which touches every required layers to meet requirements. E.g. for an ATM it would be some broad action like Logon, Deposit, Withdraw, and include actors interactions among other things. At least that how it was at the time and pretty much how Uncle Bob views it, there are a few example in the book.
- The boundary-control-entity (BCE) pattern organises the responsibilities of classes according to their role in the use-case realization:
- an entity represents long-lived information relevant for the stakeholders (i.e. mostly derived from domain objects, usually persistent);
- a boundary encapsulates interaction with external actors (users or external systems);
- a control ensures the processing required for the execution of a use-case and its business logic, and coordinates, sequences controls other objects involved in the use-case.
-
the BCE-control is very different from MVC-controller, since it encapsulates also use-case business logic whereas the MVC controller processes user input which would be of the responsibility of the boundary in BCE. The BCE control increases separation of concerns in the architecture by encapsulating business logic that is not directly related to an entity. The BCE can be used in conjunction with the hexagonal architecture, whenever the boundaries form the outer adapter layer.
BCE is compatible with the clean architecture which merges BCE principles with other architectural design paradigms. Clean architecture places entities at the core, and surround them with a use-case ring (i.e. BCE control) and a ring with gateways and presenters (i.e. BCE boundaries). However, clean architecture requires a one-way dependency from outside to inside, which requires to split BCE controls into use-case logic and object coordination.
So being flexible, feature-based, testable without loading unnecessary stuff and protecting the code from external forces, that’s what CA is about, mostly.
Screaming Architecture
So what does the architecture of your application scream? When you look at the top level directory structure, and the source files in the highest level package; do they scream: Health Care System, or Accounting System, or Inventory Management System? Or do they scream: Rails, or Spring/Hibernate, or ASP?
read Ivar Jacobson’s seminal work on software architecture: Object Oriented Software Engineering. Notice the subtitle of the book: _A use case driven approach._ In this book Ivar makes the point that software architectures are structures that support the use cases of the system. Just as the plans for a house or a library scream about the use cases of those buildings, so should the architecture of a software application scream about the use cases of the application.
Frameworks are tools to be used, not architectures to be conformed to. If your architecture is based on frameworks, then it cannot be based on your use cases.
The reason that good architectures are centered around use-cases is so that architects can safely describe the structures that support those use-cases without committing to frameworks, tools, and environment.
A good software architecture allows decisions about frameworks, databases, web-servers, and other environmental issues and tools, to be deferred and delayed. A good architecture makes it unnecessary to decide on Rails, or Spring, or Hibernate, or Tomcat or MySql, until much later in the project. A good architecture makes it easy to change your mind about those decisions too. A good architecture emphasizes the use-cases and decouples them from peripheral concerns.
Vertical Slice Architecture
So what is a “Vertical Slice Architecture”? In this style, my architecture is built around distinct requests, encapsulating and grouping all concerns from front-end to back. You take a normal “n-tier” or hexagonal/whatever architecture and remove the gates and barriers across those layers, and couple along the axis of change: 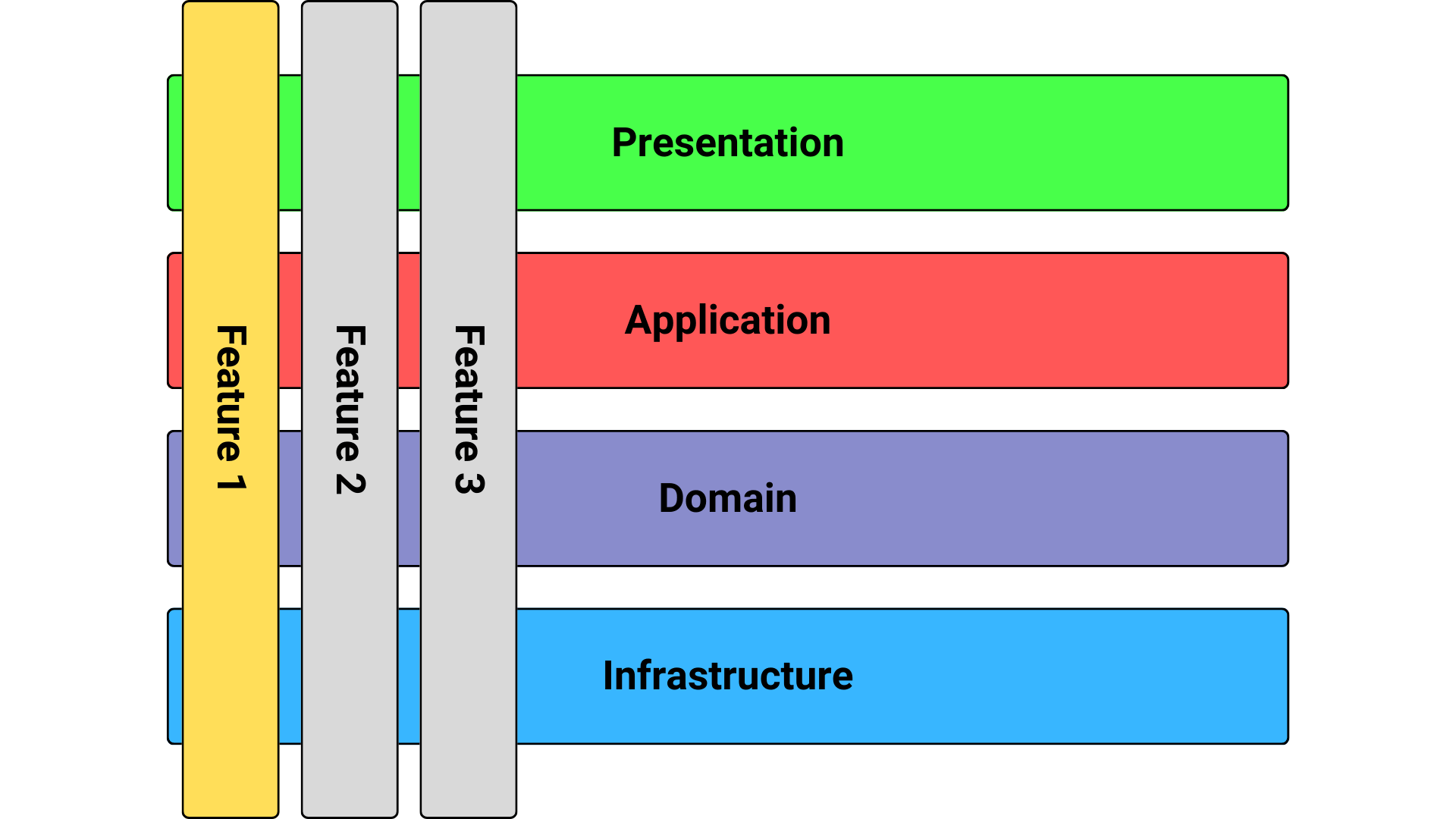 A vertical slice represents a self-contained unit of functionality. It’s a slice through the entire application stack. It encapsulates all the code and components necessary to fulfill a specific feature. In traditional layered architectures, code is organized horizontally across the various layers. One feature implementation can be scattered across many layers. Changing a feature requires modifying the code in multiple layers.
A vertical slice represents a self-contained unit of functionality. It’s a slice through the entire application stack. It encapsulates all the code and components necessary to fulfill a specific feature. In traditional layered architectures, code is organized horizontally across the various layers. One feature implementation can be scattered across many layers. Changing a feature requires modifying the code in multiple layers.
VSA addresses this by grouping all the code for a feature into a single slice.
This shift in perspective brings several advantages:
- Improved cohesion: Code related to a specific feature resides together, making it easier to understand, modify, and test.
- Reduced complexity: VSA simplifies your application’s mental model by avoiding the need to navigate multiple layers.
- Focus on business logic: The structure naturally emphasizes the business use case over technical implementation details.
- Easier maintenance: Changes to a feature are localized within its slice, reducing the risk of unintended side effects.
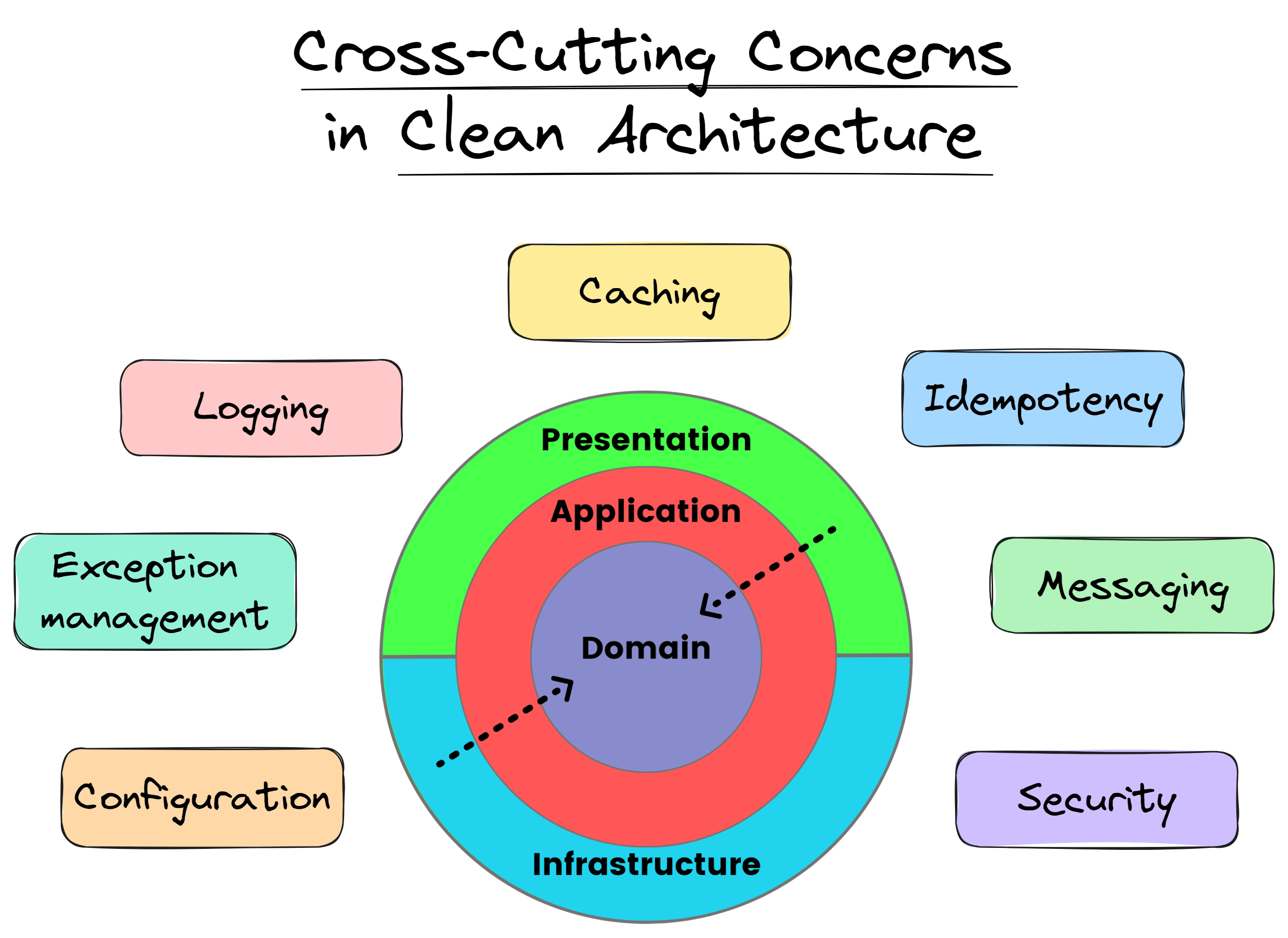
A vertical slice is likely either a command or a query. This approach gives us CQRS out of the box. Vertical slices usually need to solve some cross-cutting concerns.
The basic premise of CQS is splitting an object’s methods into Commands and Queries.
- Commands: Change the state of a system but don’t return a value
- Queries: Return a value and don’t change the state of the system (no side effects)
This doesn’t mean a command can never return a value. A typical example is popping a value from a stack. It returns a value and changes the state of the system. But the intent is what matters here.
CQS is a principle. You can follow this principle if it makes sense, but be pragmatic.
CQRS is the evolution of CQS. CQRS works on the architectural level. At the same time, CQS works on the method (or class) level.
Here’s a high-level overview of a CQRS system using multiple databases. Commands update the write database. Then, you need to synchronize the updates with the read database. This introduces eventual consistency to CQRS systems.
Eventual consistency significantly increases the complexity of your application. You must consider what happens if the synchronization process fails, and have a fault tolerance strategy.

VSA excels at managing self-contained features. However, real-world applications often involve complex interactions and shared logic.
Here are a few strategies you can consider to address this:
- Decomposition: Break down complex features into smaller, more manageable vertical slices. Each slice should represent a cohesive piece of the overall feature.
-
Refactoring: When a vertical slice becomes difficult to maintain, you can apply some refactoring techniques. The most common ones I use are
Extract methodandExtract class. - Extract shared logic: Identify common logic that’s used across multiple features. Create a separate class (or extension method) to reference it from your vertical slices as needed.
- Push logic down: Write vertical slices using procedural code, like a Transaction Script. Then, you can identify parts of the business logic that naturally belong to the domain entities.