DuckDB
Fast Top N Aggregation and Filtering with DuckDB
- TL;DR: find the top N values or filter to the latest N rows faster and easier with the N parameters in the min, max, min_by, and max_by aggregate functions
Top N
-
A common pattern when analyzing data is to look for the rows of data that are the highest or lowest in a particular metric
- A Top-N query is a SQL query that retrieves the top or bottom N rows from a table sorted by a particular column
Naive alternative for querying the min/max summary statistics of one or more columns
- ORDER BY and LIMIT will sort by the metric of interest and only return N rows
- DuckDB’s helpful COLUMNS expression can be used to calculate the maximum value for all columns
Traditional Top N by Group
- The way to filter to the Top N within a group is to use a window function or analytic function, which can use multiple rows to calculate a value for each row (whereas an aggregate function returns a single value for multiple rows), and a common table expression, views that are limited in scope to a particular query.
WITH ranked_lineitem AS (
FROM lineitem
SELECT
*,
row_number() OVER
(PARTITION BY l_suppkey ORDER BY l_shipdate DESC)
AS my_ranking
)
FROM ranked_lineitem
WHERE
my_ranking <= 3;Top N in DuckDB
-
DuckDB added the functions
min,max,min_by, andmax_byall now accept an optional parameterN. IfNis greater than 1 (the default), they will return an array of the top values.
FROM lineitem
SELECT
max(l_shipdate, 3) AS top_3_shipdates;Top N by Column in DuckDB
- we can retrieve the 3 top values in each column
FROM lineitem
SELECT
max(COLUMNS(*), 3) AS "top_3_\0";Top N by Group in DuckDB
- this query will return the ids of the 3 most recently shipped orders for each supplier
FROM lineitem
SELECT
l_suppkey,
max_by(l_orderkey, l_shipdate, 3) AS recent_orders
GROUP BY
l_suppkey;-
the
max_byfunc is an aggregate func, so it takes advantage of DuckDB’s fast hash aggregation- DuckDB’s parallel aggregate hash table can efficiently aggregate over many rows that would not fit in memory; DuckDB can evict persistent data from memory to free up space for a large hash table.
-
However, the query returns results as a LIST rather than as separate rows
-
We have the
unnestfunc to split LIST into separate rows
-
We have the
FROM lineitem
SELECT
l_suppkey,
unnest(
max_by(l_orderkey, l_shipdate, 3)
) AS recent_orders
GROUP BY
l_suppkey;-
Next we want to see the l_shipddate associated with the returned l_orderkey values
- DuckDB allows us to refer to the entire contents of a row as if it were just a single column
FROM lineitem
SELECT
l_suppkey,
unnest(
max_by(lineitem, l_shipdate, 3)
) AS recent_orders
GROUP BY
l_suppkey;The Final Top N Group Query
-
Passing one more argument to UNNEST will split this out into separate columns by running recursively.
- Once to convert each LIST into separate rows
- And then again to convert each STRUCT into separate columns.
FROM lineitem
SELECT
unnest(
max_by(lineitem, l_shipdate, 3),
recursive := 1
) AS recent_orders
GROUP BY
l_suppkey;Using DuckDB, PDAL, and Python to Curate Point Clouds into GeoParquet and GeoTIFF
-
So were going to find the Top N in a geospatial context.
-
We want to find the maximum draft value for AIS shipping traffic vessels within spatial bins.
- Grouping by the spatial index annd extracting the maximum draft value using a nested structure.
-
We want to find the maximum draft value for AIS shipping traffic vessels within spatial bins.
-
DuckDB can release Python’s GIL for its internal processes
- DuckDB can register a DataFrame as a SQL Table View, making it possible to multithread and multiprocess Python DataFrames directly using DuckDB.
-
DuckDB handles concurrent reading without hasslee but requires a lock for concurrent writing
-
use
import threadingandwith thread.Lock():...inside ofconcurrent.features()to manage a single DuckDB connection in a thread pool.
-
use
Using Dagster-DuckDB PandasIOManager
Sorting on Insert for Fast Selective Queries
TL;DR Sorting data when loading can speed up selective read queries by an order of magnitude, thanks to DuckDB’s automatic min-max indexes (also known as zone maps). This approach applies to most columnar file formats and databases as well. This will unpack the DuckDB file structure as an example of a columnar data format and gives practical advice for using sorting to improve the speed of queries
The fastest way to read data is to read as little as possible
DuckDB's Partial Reading Support
Use Cases
-
When read performance is more critical than write performance
-
add ordering steps deliberately to speed up reads
-
helpful when:
- Your dataset is large and doesn’t fit entirely in memory
- You only want to read a portion of your dataset for each query
- You access your data via HTTP(S)
- Your data lives in the cloud on object storage such as AWS S3
-
helpful when:
-
add ordering steps deliberately to speed up reads
-
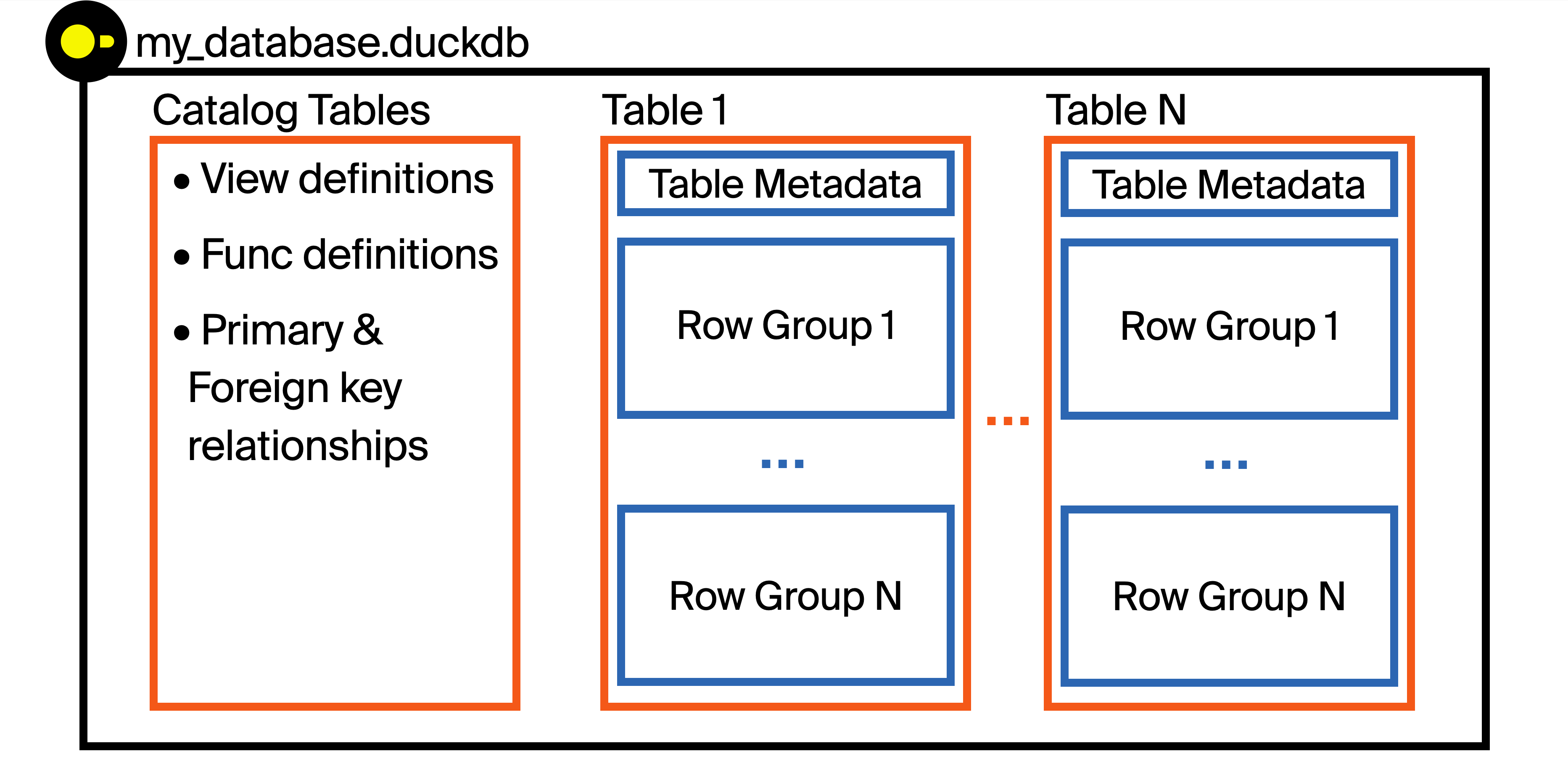
Each database file can store multiple tables, views, functions, indexes, annd primary/foreign key relationships all in the same file.
-
Before storing data, DuckDB breaks tables up into chunks of rows called row groups.
- Each row group is 122,880 rows by default
-
Within each row group, the data related to a single column is stored contiguously together on disk in one or more blocks.
-
DuckDB compresses this data to reduce file size
-
DuckDB compresses this data to reduce file size
-
Before storing data, DuckDB breaks tables up into chunks of rows called row groups.
Using Zone Maps to Skip Reading Data
-
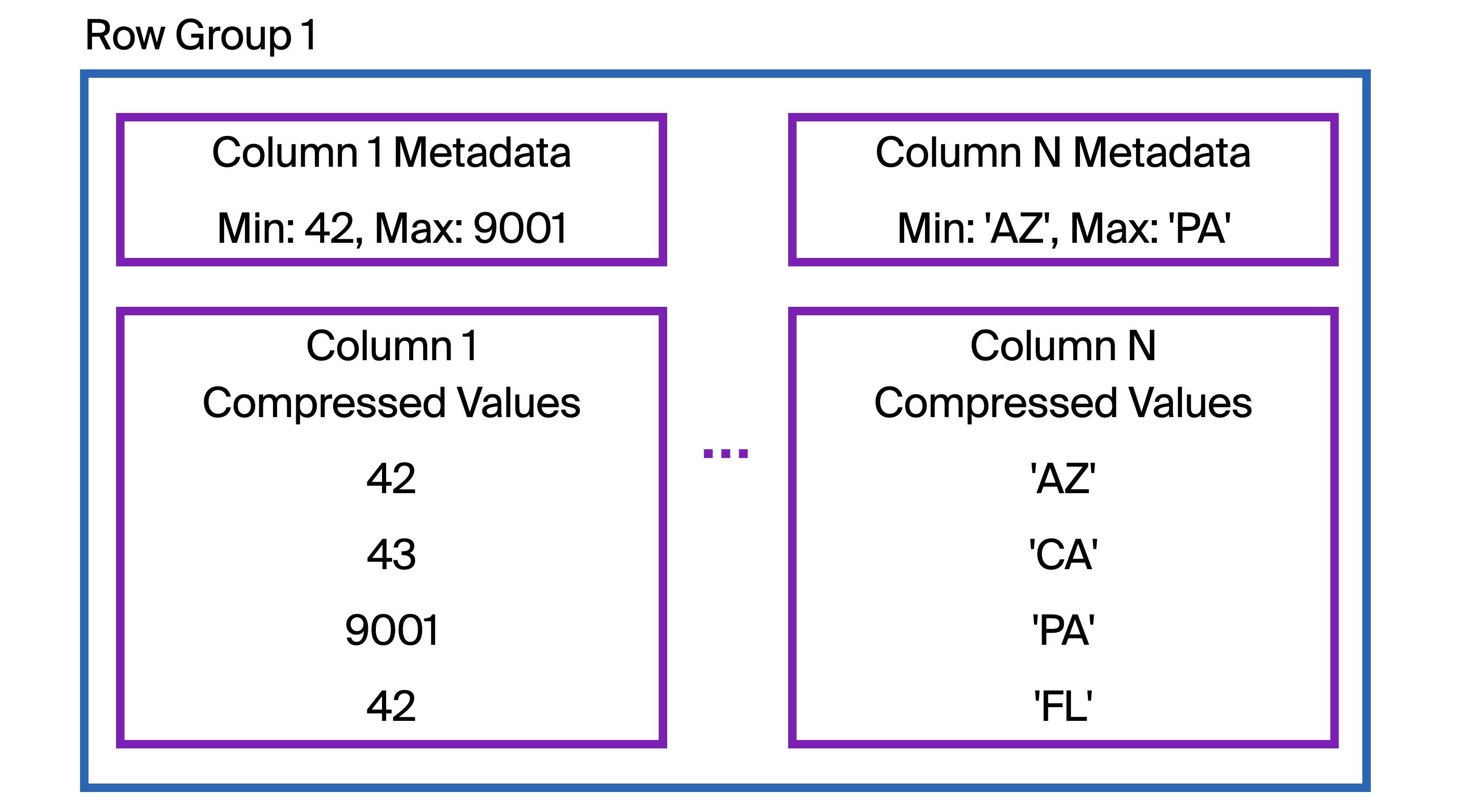
At the start of the column data stored within each row group, DuckDB also stores metadata about the column being stored, including the minimum and maximum values of that column within that row group.
- called zone maps or min-max indexes
FROM "Table 1"
WHERE "Column N" = 'VA';-
DuckDB first checks the zone map ( labeled
Column N Metadatain the diagram )
Strategically Skipping Data
-
Each subset of the data we want to retrieve should only be stored in a few row groups.
- DuckDB’s multithreading model is based on row groups, you should still see high performance as long as the number of row groups is less than the number of threads (~= CPU cores) DuckDB is using.
Sorting Best Practices
- A basic approach would be to sort by all columnns that are used as filters, beginning with the columns used most often.
-
An approach if the workload involves filtering by multiple different columns is to consider sorting first by columns with the lowest cardinality (the fewest unique values).
-
Timestamps are frequently very high cardinality
- As a result, sorting by lower cardinality columns first is more helpful
- It is more beneficial to sort by a timestamp rounded to the closest window of time and other column values.
-
Timestamps are frequently very high cardinality
- To benefit from min-max indexes, a WHERE clause must filter directly on a specific column, not on a calculated expression. If an expression is used, it must be evaluated for each row, so no row groups can be skipped!
Avoid Small Inserts
-
There is not an opportunity to sort data when it is being inserted if workloads are inserted in small batches or single rows at a time.
- Bulk inserts or batching will allow the sorting to work effectively
- There can be a periodic re-sorting job, which is analogous to a re-indexing task in transactional systems.
Sort In Chunks
-
One way to reduce memory/disk usage when sorting is to process the table in pieces by looping through multiple SQL statements, each filtered to a specific chunks.
- SQL does not have a looping construct, this would be handled by a host language like Python,Jinja, etc.
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
WITH NO DATA;
for chunk in chunks:
INSERT INTO sorted_table
FROM unsorted_table
WHERE chunking_column = chunk
ORDER BY other_columns...;- May take longer to run since data must be scanned once per chunk, but memory use is likely to be much lower
Sort the First Few Characters of String
-
In the zone maps of
VARCHARcolumns, DuckDB stores just the first 8 bytes of the min and max string values.- There is no need to sort more than the first 8 bytes (8 ASCII characters)
-
DuckDB’s radix sort algorithm is sensitive to the length of strings by design.
-
time complexity is
O(nk), wherenis the number of rows, andkis the width of the sorting key
-
time complexity is
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
ORDER BY varchar_column_to_sort[:8]; -- bracket notation for string slicingFilter by More Columns
-
Adding filters to a
WHEREclause can be helpful if those columns being filtering have any kind of approximate order.
Adjust the Row Group Size
-
The number of rows within a row group can be tuned for specific workloads (
ROW_GROUP_SIZE)- There is an overhead of checking metadata more often when row groups are smaller
-
If a large table is being queried selectively, then a larger row group size can reduce the number of metadata checks that are neccesary to reach the recent data.
- Each row group is larger as a tradeoff
-
A row group size should be a power of 2, minmum being 2048; the vector size of DuckDB
ATTACH './smaller_row_groups.duckdb' (ROW_GROUP_SIZE 8192);
Faster Dashboards with Multi-Column Approximate Sorting
- TL;DR; With any columnar data format, using advanced multi-column sorting when loading data can improve performance on wide variety of selective read queries. Space filling curve encodings like Morton (Z-Order) and Hilbert approximately sort multiple columns together. Sorting by rounded timestamps adds additional benefits when filtering on recent data.
When queries read a subset of the total rows, sorting data while loading can have benefits, SEE Sorting On Insert For Fast Selective Queries
-
Queries filter on different columns
-
Query patterns are not perfectly predictable
-
Queries filter by time and at least one other column
-
We want to sort approximately by a large number of columnss to benefit from min-max indexes/zone maps
Space Filling Curves
- Both Morton and Hilbert are space filling curves algorithms that are designed to combine mulitple columns into an order that preserves some approximate ordering for both columns
Geospatial Analytics Use Case
- If a dataset contained latitude and longitude coordinates of every cafe on earth, but we wanted to sort so that cafes that are physically close to one another are near each other in the list, we could use a space filling curve.
-
Cafes somewhat close recieve similar Morton/Hilbert encoding value.
- Allowing to quickly execute queries
-
Both Hilbert and Morton operate on integers and floats, but this outlines a way to use them to sort
VARCHARcolumn into an integer as a pre-processing step.
Truncated Timestamps
-
Don’t just sort the timestamp column because it can be very granular
-
To sort on multiple columns as well as a time column
- First sort by a truncated timestamp and then on the other columns
-
To sort on multiple columns as well as a time column
Morton and Hilbert sorting queries
-
The Morton and Hilbert encoding functions come from lindel DuckDB community extension
- The morton_encode and hilbert_encode functions from the lindel community extension can then be used within the ORDER BY clause to sort by the Morton or Hilbert encoding.
INSTALL lindel FROM community;
LOAD lindel;
CREATE TABLE IF NOT EXISTS flights_morton AS
FROM flights
ORDER BY
morton_encode([
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3)
]::UBIGINT[2]);
CREATE TABLE IF NOT EXISTS flights_hilbert AS
FROM flights
ORDER BY
hilbert_encode([
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3)
]::UBIGINT[2]);-
The spatial extension also contains ST_Hilbert function that works similarly
- the spatial extension can be used to execute a Hilbert encoding. It requires a bounding box to be supplied, as this helps determine the granularity of the encoding for geospatial use cases.
SET VARIABLE bounding_box = (
WITH flights_converted_to_ubigint AS (
FROM flights
SELECT
*,
varchar_to_ubigint(origin, num_chars := 3) AS origin_ubigint,
varchar_to_ubigint(dest, num_chars := 3) AS dest_ubigint
)
FROM flights_converted_to_ubigint
SELECT {
min_x: min(origin_ubigint),
min_y: min(dest_ubigint),
max_x: max(origin_ubigint),
max_y: max(dest_ubigint)
}::BOX_2D
);
CREATE OR REPLACE TABLE flights_hilbert_spatial AS
FROM flights
ORDER BY
ST_Hilbert(
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3),
getvariable('bounding_box')
);Approximate Time Sorting
- Sorting by an “approximate time” involves truncating the time to the nearest value of a certain time granularity
CREATE TABLE IF NOT EXISTS flights_hilbert_day AS
FROM flights
ORDER BY
date_trunc('day', flightdate),
hilbert_encode([
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3)
]::UBIGINT[2]);
CREATE TABLE IF NOT EXISTS flights_hilbert_month AS
FROM flights
ORDER BY
date_trunc('month', flightdate),
hilbert_encode([
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3)
]::UBIGINT[2]);
CREATE TABLE IF NOT EXISTS flights_hilbert_year AS
FROM flights
ORDER BY
date_trunc('year', flightdate),
hilbert_encode([
varchar_to_ubigint(origin, num_chars := 3),
varchar_to_ubigint(dest, num_chars := 3)
]::UBIGINT[2]);-
When querying a week of data for a specific
origin, sorting at the daily level performs the best-
Sorting by a more approximate time (month or year) performs better because the more approximate time buckets allow Hilbert encoding to separate
origins into different row groups more effectively.
-
Sorting by a more approximate time (month or year) performs better because the more approximate time buckets allow Hilbert encoding to separate
-
Querying by time and destination follows a very similar pattern, with the ideal sort order being highly dependent on how far back in time is analyzed.
-
Filtering by
orignanddestinationshows a very different outcome, with a yearly granularity being superior across the board.-
The
originanddestinationfilters are much more effective at skipping row groups when the timestamp ordering is very approximate.
-
The
-
Filtering by
Table Creation Time
-
The investment in sorting data when inserting requires more time, but you won’t have an empty dashboard
- Ideally create a DuckDB table from parquet files
Measuring Sortedness
-
the most effective way to choose a sort order is to observe your production workload
- This is not always feasible, instead we can measure how well sorted the dataset is on the columns of interest.
- For selective queries to work effectively, each value being filtered on should only be present in a small number of row groups
Conclusion
-
Storing data in a columnar format and sorting by multiple columns can lead to fast read queries acrosss a variety of query patterns.
- Sorting using Hilbert encoding provided high performance across multiple workloads, and sorting by year and then by Hilbert performed well when also filtering by name
-
Thanks to
Number of Row Groups per Valuecalculation, we can measure sortedness of any table by column, and it was predictive of the experimental performance we observed.- We can quickly forecast the effectivenesss of different sorting approaches, without having to benchmark read workloads each time